
생성형 AI의 진화가 발 빠르게 진행 중이다. 이번에는 비디오 사운드 트랙이다. 영화나 드라마에 삽입되는 사운드 트랙은 선택이 아닌 필수다. 장면에 맞는 음악과 음향 효과로 의미와 감정을 전달하는 데 절대적인 역할을 하기 때문이다. 하지만 전문가가 아니라면 쉽게 다가갈 수 있는 영역이 아니다.
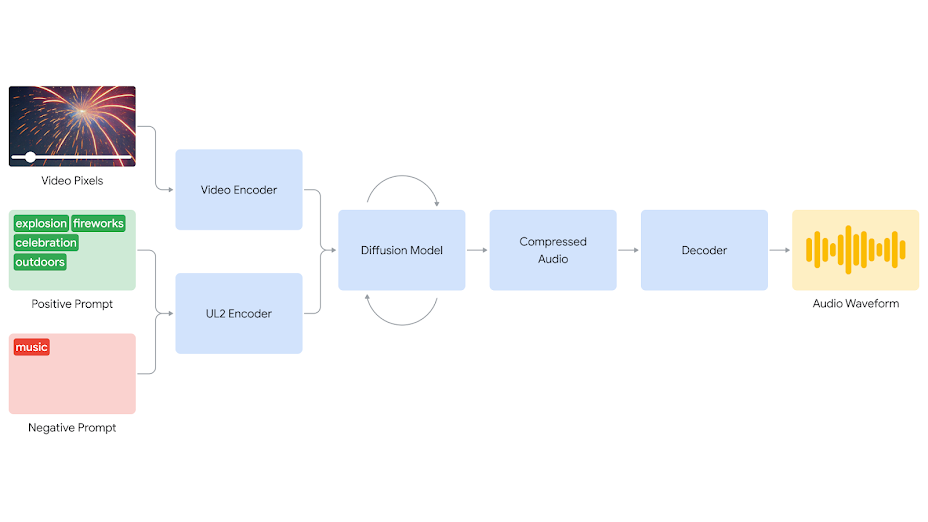
구글 딥마인드(DeepMind)가 비디오 픽셀과 텍스트 프롬프트를 기반으로 사운드 트랙을 생성하는 V2A(video-to-audio) 기술 개발에 대한 진행 상황을 공개했다. V2A는 동영상 속의 화면(픽셀) 분석과 자연어로 입력한 텍스트 프롬프트를 결합해, 현재 장면에 어울리는 극적인 음악과 사실적인 사운드 효과 등을 생성하는 AI 기술이다.
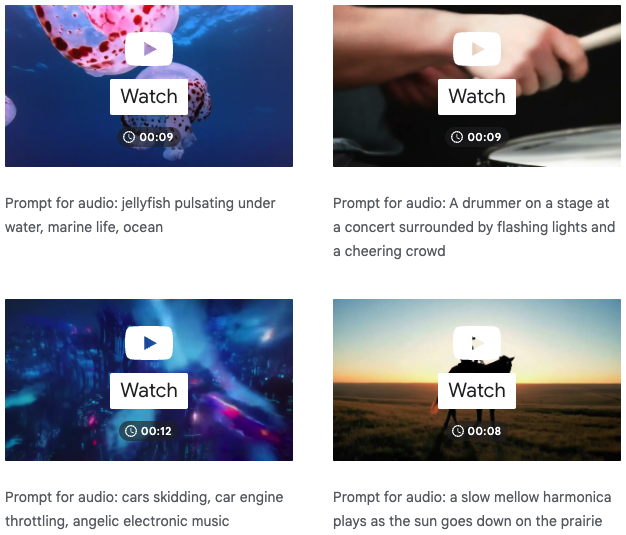
V2A는 지금 시작인 만큼 좀 더 진화와 발전을 거쳐야 하지만, 음악과 음향에 대한 전문적인 지식 없이 소리 없는 영상에 생명을 불어넣을 수 있는 기술로 주목할만하다. 특히, 구글 딥마인드의 베오(Veo)처럼 생성형 AI 비디오 모델과 함께 사용할 경우, 동영상에 필요한 모든 요소를 생성형 AI로 제작하는 것도 머지않아 가능할 전망이다.
예를 들어 어두운 지하 통로를 걸어가는 영상에 ‘영화, 스릴러, 공포 영화, 음악, 긴장감, 분위기, 콘크리트 위의 발자국’이라는 텍스트 프롬프트를 입력하면, 해당 장면의 픽셀을 분석하고 텍스트 프롬프트를 결합해 사운드 트랙을 생성한다. 딥마인드는 V2A가 모든 비디오 입력에 대해 무제한의 사운드트랙을 생성할 수 있다고 밝혔다.
딥마인드는 “우리는 가장 확장성이 뛰어난 AI 아키텍처를 찾기 위해 자동 회귀 및 확산 접근법을 실험한 결과, 오디오 생성에 대한 확산 기반 접근법이 비디오와 오디오 정보를 동기화하는 데 가장 현실적이고 설득력 있는 결과를 제공했다”며 V2A가 확산 접근법을 기반으로 한다고 밝혔다.
또한, “V2A 시스템은 비디오 입력을 압축된 표현으로 인코딩하는 것으로 시작한다. 그런 다음 확산 모델이 무작위 노이즈로부터 오디오를 반복적으로 정제한다. 이 과정은 시각적 입력과 자연어 프롬프트에 따라 안내되어 프롬프트와 밀접하게 일치하는 동기화되고 사실적인 오디오를 생성한다. 마지막으로 오디오 출력이 디코딩되어 오디오 파형으로 변환되고 비디오 데이터와 결합한다”고 작동 원리를 설명했다.
이번 연구는 영상에 있는 픽셀(raw pixels)을 이해할 수 있고, 텍스트 프롬프트를 추가하는 것은 선택 사항이라는 점이 기존의 비디오-오디오 솔루션과 다른 점이라고 딥마인드는 전했다. 아울러 사운드, 시각적 요소, 타이밍 등의 다양한 요소를 조정하는 작업을 수동으로 하지 않아도 된다는 것도 장점으로 꼽았다.
딥마인드는 모델의 학습 범위(model’s training distribution)를 벗어나거나 왜곡으로 인한 오디오 품질 저하, 입력된 스크립트에서 음성을 생성하고 이를 캐릭터 움직임과 자연스럽게 동기화하는 립싱크 개선(lip-syncing) 등이 향후 연구 과제라고 밝혔다.
⧉ Syndicated to WWW.CIOKOREA.COM
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| ‘찾는’ 쇼핑에서 ‘묻는’ 쇼핑으로…아마존, AI 도우미 ‘루퍼스’ 미국 고객 대상 서비스 시작 (0) | 2024.07.16 |
|---|---|
| “AI 상담원 도입하면 경쟁사로 옮길 수도”…가트너, 64%의 고객 AI 상담 원하지 않아 (0) | 2024.07.11 |
| ‘검증된 실적, 전문성, 투자자, 사례 및 결과’…CB인사이츠의 AI 기업 평가 기준 (0) | 2024.07.09 |
| AI가 환자 맞춤형 치료 도우미…컬러 헬스, 오픈AI와 협력해 코파일럿 공개 (0) | 2024.06.20 |
| “AI 교육과 활용 지침없으면 효율성 떨어져”…AI로 절약한 시간 여전히 관리 업무에 사용 (0) | 2024.06.11 |
| 이상있는 배송 상품 족집게처럼 골라낸다…아마존, 프로젝트 PI로 고객 경험 & 배송 효율 개선 (0) | 2024.06.07 |
| ‘상상하는 소리를 현실로 만든다’…일레븐랩, 음향 효과 생성 AI 도구 출시 (0) | 2024.06.04 |
| 사람처럼 빠르게 이해하고 빠르게 답변…오픈AI, 플래그십 LLM ‘GPT-4o’ 발표 (0) | 2024.05.14 |



