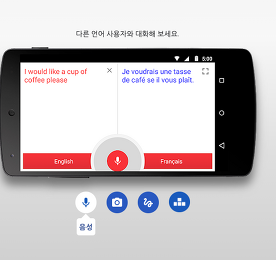
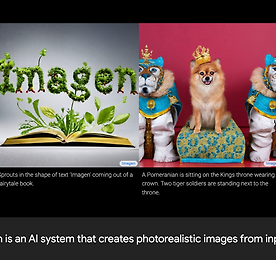
생각하는 대로 이미지 생성, 다양한 형태로 사람과 소통...AI는 멀티모달로 진화중
소식이나 기술로 접하는 인공지능은 '나'와 조금은 동떨어져 보이지만, 실생활 속에 인공지능은 이미 '나'의 삶 곳곳에 자리를 잡고 있다. 인터넷 포털 속에서 제공하는 수 많은 정보나 검색 엔진부터 메신저, 스트리밍, 게임, 음성 비서, 사진이나 동영상 앱 등 이미 수 많은 곳에서 인공지능이 활약하고 있다. 하지만 지금까지의 인공지능은 인간의 감각이나 능력 중에서 어느 한 가지에 초점을 맞춰 특화 시킨 것이 대부분이다. 예를 들어 문자와 문장을 인식하고 분석해 검색이나 번역에 활용하고, 음성으로 정보를 주고 받는 음성 기반 인공지능 비서, 영상이나 동영상 속의 사물이나 문자를 인식하고 구분하는 것이 그렇다. | 텍스트-이미지 또는 언어-이미지 등 여러 채널로 상호작용하는 멀티모달 AI 컴퓨터, 스마트폰, ..
2022. 12. 9.
더보기
생각하는 대로 이미지 생성, 다양한 형태로 사람과 소통...AI는 멀티모달로 진화중
소식이나 기술로 접하는 인공지능은 '나'와 조금은 동떨어져 보이지만, 실생활 속에 인공지능은 이미 '나'의 삶 곳곳에 자리를 잡고 있다. 인터넷 포털 속에서 제공하는 수 많은 정보나 검색 엔진부터 메신저, 스트리밍, 게임, 음성 비서, 사진이나 동영상 앱 등 이미 수 많은 곳에서 인공지능이 활약하고 있다. 하지만 지금까지의 인공지능은 인간의 감각이나 능력 중에서 어느 한 가지에 초점을 맞춰 특화 시킨 것이 대부분이다. 예를 들어 문자와 문장을 인식하고 분석해 검색이나 번역에 활용하고, 음성으로 정보를 주고 받는 음성 기반 인공지능 비서, 영상이나 동영상 속의 사물이나 문자를 인식하고 구분하는 것이 그렇다. | 텍스트-이미지 또는 언어-이미지 등 여러 채널로 상호작용하는 멀티모달 AI 컴퓨터, 스마트폰, ..
2022. 12. 9.
더보기
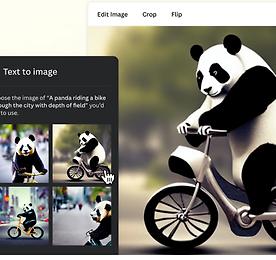 비즈니스용 이미지도 AI가 뚝딱!...디자인 플랫폼 캔바, 텍스트-이미지 AI 출시
스테이블 디퓨전(Stable Diffusion)은 만들고 싶은 이미지에 대한 설명을 문자로 입력하면, 이를 참조해 인공지능이 이미지를 생성하는 문자-이미지 생성 AI다. 독일의 뮌헨 대학교 머신 비전 러닝 그룹(Machine Vision & Learning Group) 연구를 기반으로, 스태빌리티 AI(Stability AI)와 런웨이 ML(Runway ML)의 지원과 협력으로 탄생했다. 호주 시드니에 본사를 둔 그래픽 디자인 플랫폼 캔바(Canva)는 SNS에 활용할 수 있는 다양한 이미지와 동영상, 마케팅 업무에 필요한 명함, 전단지, 로고, 포스터, 브로셔용 이미지, 비즈니스용 문서에 사용할 수 있는 프레젠테이션, 그래프, 플래너 등의 자료를 무료 또는 유료로 제공한다. 인쇄물 제작이나 카드나 초대..
2022. 11. 14.
더보기
비즈니스용 이미지도 AI가 뚝딱!...디자인 플랫폼 캔바, 텍스트-이미지 AI 출시
스테이블 디퓨전(Stable Diffusion)은 만들고 싶은 이미지에 대한 설명을 문자로 입력하면, 이를 참조해 인공지능이 이미지를 생성하는 문자-이미지 생성 AI다. 독일의 뮌헨 대학교 머신 비전 러닝 그룹(Machine Vision & Learning Group) 연구를 기반으로, 스태빌리티 AI(Stability AI)와 런웨이 ML(Runway ML)의 지원과 협력으로 탄생했다. 호주 시드니에 본사를 둔 그래픽 디자인 플랫폼 캔바(Canva)는 SNS에 활용할 수 있는 다양한 이미지와 동영상, 마케팅 업무에 필요한 명함, 전단지, 로고, 포스터, 브로셔용 이미지, 비즈니스용 문서에 사용할 수 있는 프레젠테이션, 그래프, 플래너 등의 자료를 무료 또는 유료로 제공한다. 인쇄물 제작이나 카드나 초대..
2022. 11. 14.
더보기
 실시간 3D 감지 모델과 벤치마크 지원...구글, '오브젝트론 데이터 세트' 출시
구글이 컴퓨터 비전 분야의 기계 학습 과정에서 활용할 수 있는, 3D 비디오 클립 모음인 '오브젝트론(Objectron) 데이터 세트'를 발표했다. 오브젝트론 데이터 세트는 다양한 각도에서 더 많은 공통 객체를 담고 있는 객체 중심의 비디오 클립 모음으로, 실시간으로 3D 객체를 감지하는 기계 학습과 벤치마킹 등에서 활용할 수 있다. 기계 학습 기반의 컴퓨터 비전 기술을 구현하려면, 효율적인 알고리즘과 방대하고 정확한 학습 데이터가 필요하다. 학습하는 방법과 과정이 우수해야 하고, 학습에 필요한 양질의 데이터는 많을수록 좋다. 이렇게 학습된 인공지능 기술을 3D 객체를 감지, 분석, 이해하는 데 적용하면, 증강 현실, 로봇 공학, 이미지 검색 등 광범위한 분야와 응용 프로그램에서 활용할 수 있는 잠재력을..
2020. 11. 11.
더보기
실시간 3D 감지 모델과 벤치마크 지원...구글, '오브젝트론 데이터 세트' 출시
구글이 컴퓨터 비전 분야의 기계 학습 과정에서 활용할 수 있는, 3D 비디오 클립 모음인 '오브젝트론(Objectron) 데이터 세트'를 발표했다. 오브젝트론 데이터 세트는 다양한 각도에서 더 많은 공통 객체를 담고 있는 객체 중심의 비디오 클립 모음으로, 실시간으로 3D 객체를 감지하는 기계 학습과 벤치마킹 등에서 활용할 수 있다. 기계 학습 기반의 컴퓨터 비전 기술을 구현하려면, 효율적인 알고리즘과 방대하고 정확한 학습 데이터가 필요하다. 학습하는 방법과 과정이 우수해야 하고, 학습에 필요한 양질의 데이터는 많을수록 좋다. 이렇게 학습된 인공지능 기술을 3D 객체를 감지, 분석, 이해하는 데 적용하면, 증강 현실, 로봇 공학, 이미지 검색 등 광범위한 분야와 응용 프로그램에서 활용할 수 있는 잠재력을..
2020. 11. 11.
더보기