
사람의 음성을 인식하거나 사람의 음성을 생성하는 AI 오디오 모델이 한 단계 진화했다. 자연스러운 구어를 사용하고, 상황에 맞는 악센트와 단어를 선택하며, 다양한 상황에 대처하며 효과적으로 소통할 수 있도록 발전한 것이다. 이를 고객 서비스를 제공하는 콜센터나 회의록 필사 등에 사용하면 이전과는 다른 AI 오디오 모델의 지원을 받을 수 있다.
오픈AI(OpenAI)가 API(API—making)를 지원하는 AI 오디오 모델 두 가지를 전 세계 개발자들을 대상으로 공개했다. 이번에 공개된 AI 모델은 사람 목소리를 인식해서 문자로 바꿔주는 ‘음성-문자’ 모델 두 가지와 문자나 문장을 음성으로 변환하는 ‘문자-음성’ 모델 한 가지다.
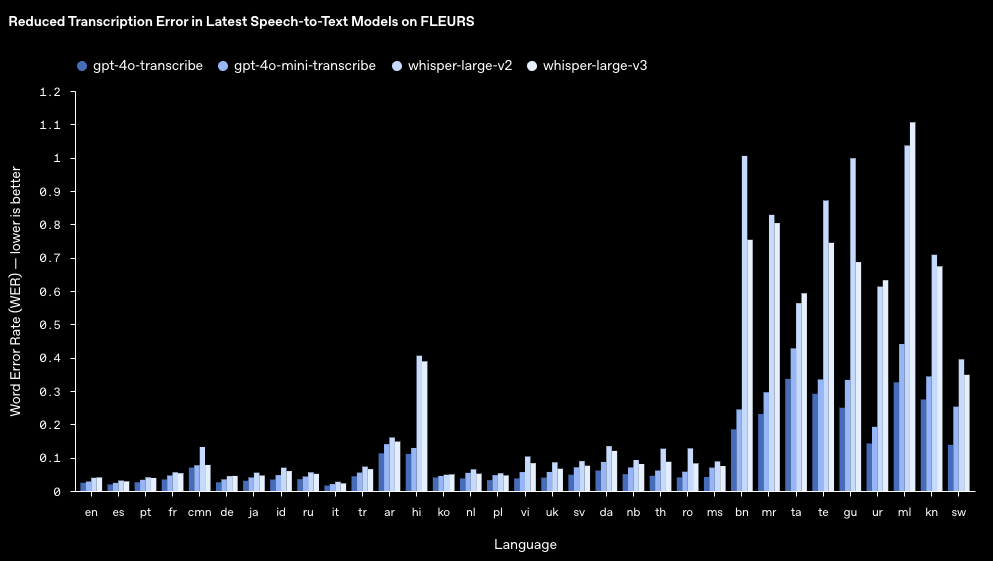
우선 음성-문자 변환 오디오 모델인 ‘gpt-4o-transcribe(지피티-4오-트랜스크라이브)와 ‘gpt-4o-mini-transcribe(지피티-4오-미니-트랜스크라이브)’는 단어 인식 오류를 줄이고, 언어 인식 및 정확도를 향상한 것이 특징이다. 이를 위해 다양한 고품질 오디오 데이터 세트를 활용한 훈련과 강화 학습(reinforcement learning) 과정을 거쳤다.
이번에 공개한 모델은 사람 음성에 담겨 있는 미묘한 뉘앙스를 더 잘 이해하고, 인식 과정에서 생기는 오류를 줄였다. 특히, 언어나 사람마다 차이가 있는 악센트, 주변 상황이 매우 시끄러운 곳에서 전달되는 음성, 말하는 속도의 차이로 인해 발생하는 인식 오류를 줄였다는 것이 오픈AI의 설명이다.
반대로 문자를 음성으로 변환하는 과정에는 ‘gpt-4o-mini-tts(지피티-4오-미니-티티에스)’를 활용할 수 있다. 이번 모델의 가장 큰 특징은 더욱 사람과 대화하는 것처럼 자연스러운 상호 작용이 가능하고, 개발자가 음성 에이전트에게 어투나 어법에 대한 사용자의 정의가 가능해졌다는 점이다.
즉, AI 에이전트와 대화하고 있는 사람에게 제대로 된 ‘내용’을 전달하는 것뿐만이라, 그것을 전달하는 소통과정에서 어떻게 전할지를 알려주는 ‘방법’에 대해서도 설정할 수 있다. 예를 들어 ‘공감하는 고객 서비스 상담원처럼 말하세요’, ‘극존칭을 사용해서 최대한 정중하게 응답하세요’ 같은 사전 설정이 가능하다.
이번에 공개한 오디오 모델은 모두 API 형태로 제공하기 때문에 개발자들이 자유롭게 활용할 수 있는 것도 장점이다. AI 오디오 모델이 제공하는 고급 음성 인식이나 합성 기능을 원하는 애플리케이션, 시스템, 솔루션에 맞게 맞춤형 에이전트로 쉽게 구축할 수 있다.
오픈AI는 “2022년에 첫 번째 오디오 모델을 출시한 이래로 모델의 지능, 정확성, 신뢰성을 개선하기 위해 노력해 왔다. 이러한 새로운 오디오 모델을 통해 개발자는 보다 정확하고 강력한 음성 텍스트 변환 시스템과 표현력이 풍부하고 개성 있는 텍스트 음성 변환 음성을 모두 API 내에서 구축할 수 있다”고 밝혔다.
⧉ Syndicated to WWW.CIOKOREA.COM
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| 로봇에겐 맞춤형 AI 모델이 필요하다..구글 딥마인드, 제미나이 2.0 기반 ‘제미나이 로보틱스’ 공개 (0) | 2025.03.20 |
|---|---|
| AI로 물 절약, 건물 관리, 냉장고 온도 제어…AWS, 아마존 기후 서약 이행에 AI 적극 활용 (0) | 2025.03.15 |
| AI가 자동차 구매 & 운전 경험도 바꾼다…세일즈포스, 에이전틱 AI는 잠재적인 게임 체인저 (0) | 2025.03.15 |
| AI 활용 연구 및 교육 혁신에 15개 기관 협력…오픈AI, NextGenAI 컨소시엄 출범 (0) | 2025.03.15 |
| 직업 적성 찾고 이력서 작성까지…구글, 구직자를 위한 AI ‘커리어 드리머’ (0) | 2025.03.15 |
| AI로 안전하고, 회복력 있고, 지속가능한 도시 개발…IBM, AI 활용 도시 개발 프로젝트 공개 (0) | 2025.02.18 |
| 생성형 AI와 데이터베이스 연결을 빠르고 효율적으로…구글, ‘생성형 AI 툴박스’ 공개 베타 발표 (0) | 2025.02.18 |
| AI 모델의 에너지 효율도 중요!…세일즈포스, ‘AI 에너지 스코어’ 발표 (0) | 2025.02.14 |



