
'대단하고 놀랍다'는 반응이 '무섭고 걱정된다'로 바뀌는 데는 오랜 시간이 걸리지 않았다. 오픈 AI가 생성형 AI인 챗GPT(ChatGPT)를 세상에 선보이고, 하루아침에 세상이 뒤바뀌고 IT 업계는 새로운 패러다임의 시대를 맞이했다. AI는 이제 모든 기술 기업의 핵심 전략이 됐고, 기술을 활용하는 기업은 AI를 선택이 아닌 필수로 여기게 됐다.
메타(Meta)가 새로운 생성형 AI인 보이스박스(Voicebox)를 공개했다. 텍스트를 입력하면 이미지를 만들어주는 오픈AI의 달・이(DALL・ E)처럼 보이스박스 역시 텍스트 입력으로 새로운 콘텐츠를 생성한다. 대신 이미지가 아니라 음성이라는 차이점이 있다. 일단 6개 언어를 지원하는 보이스박스는 비회귀적 플로우 매칭 모델(non-autoregressive flow matching model)이라는 최첨단 음성 생성 모델을 적용했다.
보이스박스에 대한 개인적인 첫인상은 '놀랍다'가 아닌 '무섭다'에 가깝다. 영어, 프랑스어, 독일어, 스페인어, 폴란드어, 포르투갈어를 지원하는 보이스박스는 주어진 텍스트를 기반으로 음성을 합성하고, 음성 속에 섞인 일시적인 잡음을 제거하며, 마음대로 음성 콘텐츠를 편집(변형)한다. 또한, 서로 다른 언어 간에 오디오 스타일을 적용하고, 텍스트를 기반으로 다양한 음성 샘플을 생성할 수 있다.
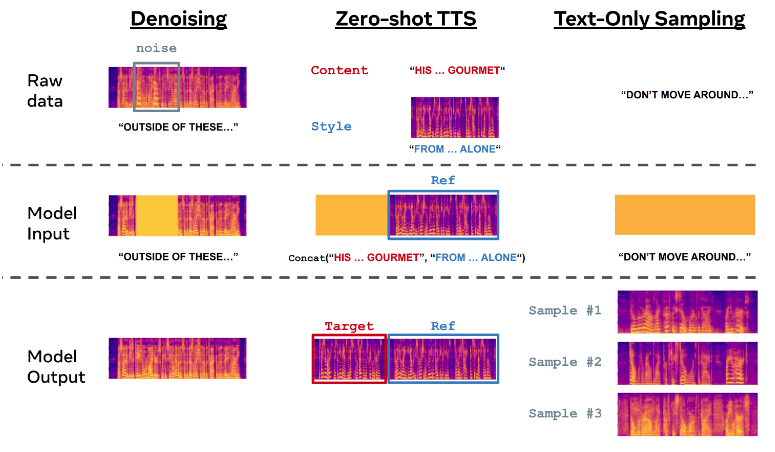
백문이불여일견(百聞不如一見)이 아니라, 백견이불여일문(百見不如一聞)이다. 보이스박스에 대한 문자로 된 설명만으로는 놀람 또는 걱정이라는 감정의 울림을 전혀 가늠할 수 없다. 메타데모랩(voicebox.metademolab.com)에 공개된 샘플 오디오를 들어보는 것이 빠르다. 메타 AI 팀은 6만 시간 분량의 데이터로 영어 전용 보이스박스를 교육하고, 나머지 언어는 5만 시간으로 데이터로 보이스박스를 교육했다.
이렇게 학습을 통해 똑똑해진 보이스박스는 2초 분량의 음성 샘플만 있으면, 억양, 음색, 톤 등을 거의 완벽하게 일치시킨 음성을 합성해서 주어진 텍스트 문장을 그대로 발음하는 오디오 파일을 생성한다. 2분이 아니라 2초다. 이 정도 길이의 음성 파일을 기반으로 인컨텍스트 학습(in-context learning)을 통해 상황에 맞는 텍스트-음성 합성(In-context text-to-speech synthesis)을 할 수 있다.
이를 제로 샷 텍스트 음성 합성(Zero-shot text-to-speech synthesis)이라 하는데, '음성, 배경 소음, 말하기 스타일 등 모든 측면에서 레퍼런스와 일관성 있는 음성을 생성한다'는 것이 메타의 설명이다. 어딘가에 남겨진 있는 2초 이상의 누군가의 목소리가 있다면, 그것을 기반으로 입력한 텍스트로 그 사람이 말한 것처럼 음성 파일을 만들 수 있다는 뜻이다.
일시적인 잡음 제거(Transient noise removal)는 대화나 연설 가운데 섞인 잡음만 콕 집어서 제거하는 기능이다. 음성 파일 중간에 시끄러운 자동차 경적, 개 짖는 소리, 비행기 소음 등 다양한 형태의 잡음이 들어간 경우, 다시 녹음할 필요 없이 보이스박스를 통해 잡음만 지울 수 있다. 잡음이 들어가지 않음 음성을 기반으로 해당 부분의 내용을 잡음이 없는 상태로 그대로 생성하고 이어주는 것이다.
콘텐츠 편집(Content editing)도 가짜 뉴스의 위험성에 대해 잘 알고 있는 사람들이 볼 때는 당황스럽다. 예를 들어 원래 말한 내용 중간에 "나는 서울에 가려고 했다'는 음성이 기록된 부분을 '나는 집에서 자고 있었다"로 어렵지 않게 바꿀 수 있다. 긍정적인 활용 사례로 본다면 대화나 강의 내용을 녹음하다가 잘 못 말한 부분이 있을 때 다시 녹음할 필요 없이 그 부분만 쉽게 수정할 수 있다.
다국어 스타일 전송(Cross-lingual style transfer)도 눈 여겨 볼만하다. 예를 들어 독일어 프롬프트로 영어를 생성할 수 있는데, 이는 독일어 발음을 분석해 억양이나 톤을 그대로 반영해 영어로 발음하는 목소리를 만들어 낸다. 이를 활용하면 영어로 촬영된 다큐멘터리 해설을 기반으로, 스페인어나 독일어 등의 다른 언어로 된 해설을 해당 성우 목소리로 바꾸어 더빙할 수 있다.
다양한 음성 생성(Diverse speech generation) 말 그대로 주어진 조건이나 자료 없이 다양한 오디오 스타일의 음성을 생성하는 것이다. 텍스트로 주어진 내용을 성별, 나이, 음색, 억양 등 다양한 형태의 사람 목소리로 생성할 수 있다. 오디오북, 시나리오 등 텍스트로 주어진 어떤 내용이든 성우나 배우 없이 얼마든지 원하는 음성 파일로 만들 수 있다.
⧉ Syndicated to WWW.CIOKOREA.COM
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| '개방과 책임으로 AI 언어 모델 혁신'...메타, MS와 차세대 LLM 라마(LIama) 2 공개 (0) | 2023.07.22 |
|---|---|
| "작업 시간 40% 단축, 작업 품질 18% 증가"...MIT, 챗GPT의 생산성 향상 연구 (0) | 2023.07.18 |
| 정보 유출없는 AI로 요약, 질문, 아이디어 ...구글, AI 기반 '노트북LM' 발표 (0) | 2023.07.13 |
| AI 규제 관련 해결 과제 4가지...가트너, '법률 시행 이전 준비해야' (0) | 2023.07.05 |
| 옷 입은 모습 가상으로 보여주는 생성 AI...구글, 온라인 의류 쇼핑에 적용 (0) | 2023.06.19 |
| '함수 호출, 더 긴 텍스트, 더 저렴한 가격'...오픈AI, 챗GPT 새로운 업데이트 발표 (0) | 2023.06.14 |
| AIaaS 시장 2028년까지 42.6% 성장 전망...기업의 AI 채택 증가가 시장 견인 (0) | 2023.06.06 |
| 19만 개 이상의 데이터 세트로 로봇 훈련...아마존, 분류 로봇 위한 ARM벤치 공개 (0) | 2023.04.18 |



